Ph.D. Student
University of Cambridge

 Bio
Bio
University of Cambridge
Republic of China Army
National Taiwan University, Digital Speech Processing and Speech Special Project
StorySense Computing, Inc, acquired by 电话帮 in 2014.
Ph.D. student in Engineering
University of Cambridge
Master of Science in Engneering
National Taiwan University
Bachelor of Science in Engineering
National Taiwan University
Recently, significant progress has been mode in applying statistical methods in automating the development of Spoken Dialogue Systems (SDS). However, they are still restricted in particular application domains and were found hard to scale or even extend to similar domains. One very reason is the ambiguous nature of human languages, which makes the three core components: speech recognition, spoken language understanding, and natural language generation the bottlenecks for scalability.
Deep learning sheds a light on these language problems. By implicitly mapping words into distributional, low-dimensional vectors, semantics and syntactics can be composited to form complex meanings or be used to make sophisticated predictions. Furthermore, neural networks can be trained end-to-end from given examples, which reduced the amount of handcrafting and manual feature engineering in the dilaogue development process. These benefits make the scalability of SDS possible in a near future.
to be appear
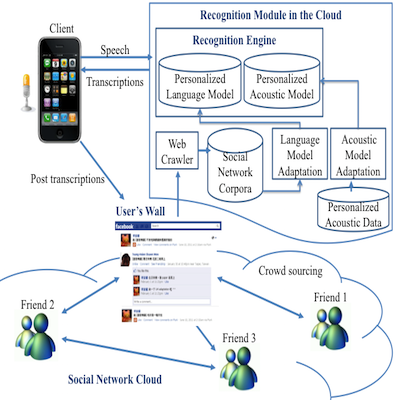
Designed a crowdsourcing platform to collect personal corpora from social network.
Built personalized language models by adopting social properties.
Compared personalization capabilities of N-gram and Recurrent Neural Network LMs.
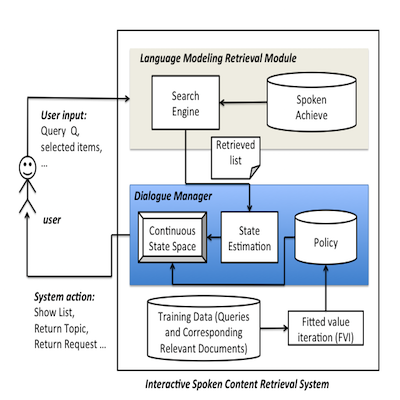
Cast interactive retrieval problems as an MDP decision framework.
Developed and compared various MDP models and reinforcement learning methods.
Implemented a state (retrieval quality) estimator to project retrieval indicators to state.
Speech recognition has become an important feature in smartphones in recent years. Different from traditional au- tomatic speech recognition, the speech recognition on smartphones can take advantage of personalized language models to model the linguistic patterns and wording habits of a particular smartphone owner better. Owing to the popularity of social networks in recent years, personal texts and messages are no longer inaccessible. However, data sparseness is still an unsolved problem. In this paper, we propose a three-step adaptation approach to personalize recurrent neural network language models (RNNLMs). We believe that its capability to model word histories as distributed representations of arbitrary length can help mitigate the data sparseness problem. Furthermore, we also propose additional user-oriented features to empower the RNNLMs with stronger capabilities for personalization. The experiments on a Facebook dataset showed that the proposed method not only drastically reduced the model perplexity in preliminary experiments, but also moderately reduced the word error rate in n-best rescoring tests.
Interactive retrieval is important for spoken content because the retrieved spoken items are not only difficult to be shown on the screen but also scanned and selected by the user, in addition to the speech recognition uncertainty. The user cannot playback and go through all the retrieved items to find out what he is looking for. Markov Decision Process (MDP) was used in a previous work to help the system take different actions to interact with the user based on an estimated retrieval performance, but the MDP state was represented by the less precise quantized retrieval performance metric. In this paper, we consider the retrieval performance metric as a continuous state variable in MDP and optimize the MDP by fitted value iteration (FVI). We also use query expansion with the language modeling retrieval framework to produce the next set of retrieval results. Improved performance was found in the preliminary experiments.
Voice access of cloud applications via smartphones is very attractive today, specifically because a smartphones is used by a single user, so personalized acoustic/language models become feasible. In particular, huge quantities of texts are available within the social networks over the Internet with known authors and given relationships, it is possible to train personalized language models because it is reasonable to assume users with those relationships may share some common subject topics, wording habits and linguistic patterns. In this paper, we propose an adaptation framework for building a robust personalized language model by incorporating the texts the target user and other users had posted on the social networks over the Internet to take care of the linguistic mismatch across different users. Experiments on Facebook dataset showed encouraging improvements in terms of both model perplexity and recognition accuracy with proposed approaches considering relationships among users, similarity based on latent topics, and random walk over a user graph.
Interaction with user is specially important for spoken content retrieval, not only because of the recognition uncertainty, but because the retrieved spoken content items are difficult to be shown on the screen and difficult to be scanned and selected by the user. The user cannot playback and go through all the retrieved items and then find out they are not what he is looking for. In this paper, we propose a new approach for interactive spoken content retrieval, in which the system can estimate the quality of the retrieved results, and take different types of actions to clarify the user’s intention based on an intrinsic policy. The policy is optimized by a Markov Decision Process (MDP) trained with Reinforcement Learning based on a set of pre-defined rewards considering the extra burden given to the user.
This thesis considers voice access of cloud applications with two parts: (1) Personalized Language Model and (2) Interactive spoken document retrieval. Model mismatch has been a major problem in speech recognition. With hand-held devices widely used today, personalized models become possible. A huge quantities of posts and comments with known owners emerged on social network websites, personal corpora become practically available but with data sparseness problem unsolved. In the first part of this thesis, we proposed personalized language modeling approaches by estimating the language similarities between different social network users and integrating the corresponding personal corpora accordingly. We studied both N-gram language models as well as recurrent neural network language models, and the experimental results support the concept. In the second part of this thesis, we studied interactive spoken document retrieval. Interactive retrieval is helpful to spoken content retrieval because retrieved spoken items are difficult to be shown on screen and browsed by the user, in addition to the speech recognition uncertainty. We model the interaction process by a Markov Decision Process and train the policy with Reinforcement Learning. Experimental results demonstrate the retrieval performance can be improved with the interactions.